


博客
编译器本质上是一种提高开发效率的工具,将高级语言转换为低级语言(通常是二进制机器码),使得程序员不需要徒手写二进制。转换过程中,首要任务是保证正确性,同时需要进行优化以提升程序的运行效率。传统意义上的编译器的输入通常是某种高级语言,输出是可执行程序。在实际工作中接触到了深度学习编译器开发,其设计思想与传统编译器非常类似,所以本文以深度学习编译器的开发、结合我们实际开发的深度学习编译器 MegCC 为例,来说明如何写一个编译器。 本文主要分为以下两个部分:
- 介绍深度学习编译器,重点介绍编译器中前端和后端的优化方法。
- 以 MegCC 为例介绍如何开发一个深度学习编译器。
深度学习编译器简介
与传统编译器不同,深度学习编译器的输入是神经网络模型、输出是可运行在不同平台的表达了输入的神经网络模型的计算过程的可执行程序。但深度学习编译器又与传统编译器类似,都分为前端和后端,前端负责执行硬件无关的优化,后端负责执行硬件相关的优化。对编译器来说,最重要的两个概念是 IR(intermediate representation, 中间表示)和 Pass。对于人类来说,抽象是理解复杂事物的一种重要方式,IR 就是对编译过程中间产物的抽象,IR 通常有多级,越高级的 IR 越抽象,越低级的 IR 越具体。Pass 定义了如何将高级 IR 逐步 lowering 到低级 IR,并负责进行优化。下面根据前端和后端进行分类,介绍优化的方法。
前端优化方法
前端首先需要根据输入的模型构建计算图,生成 high-level IR,然后进行一系列的优化。由于优化是基于计算图的,并不涉及具体计算,所以该优化是后端无关的。常见的优化手段有可分为三类:node-level optimizations;block-level optimizations; dataflow-level optimizations。
- node-level optimizations。节点层面的优化主要是消除一些不必要的节点以及将某些节点替换为代价更小的节点。比如使用矩阵 A 与一个 0 维矩阵相加,则可消除该加法操作。
- block-level optimizations。块层面的优化主要有代数简化和算子融合。 a. 代数简化,例如 A^T 和 B^T 进行矩阵乘,则可使用 B 与 A 矩阵乘之后进行转置进行替换,可节约一次转置运算。 b. 算子融合是常见的深度学习的优化手段。算子融合虽然不能减少计算量,但是可以减少访存量,提高计算访存比,从而提升性能。
- dataflow-level optimizations。数据流层面的优化主要有静态内存规划等。 a. 静态内存规划通过在不发生内存重叠的前提下尽可能复用内存,使得程序运行时所使用的内存尽可能小。
后端优化方法
后端通用的优化有循环展开、循环融合、掩盖访存等;另外根据硬件的不同,可使用基于硬件的指令映射、向量化等并行计算以及手工编写汇编 kernel 等手段进行针对性优化。图 1 展示了常用的后端优化方法 1
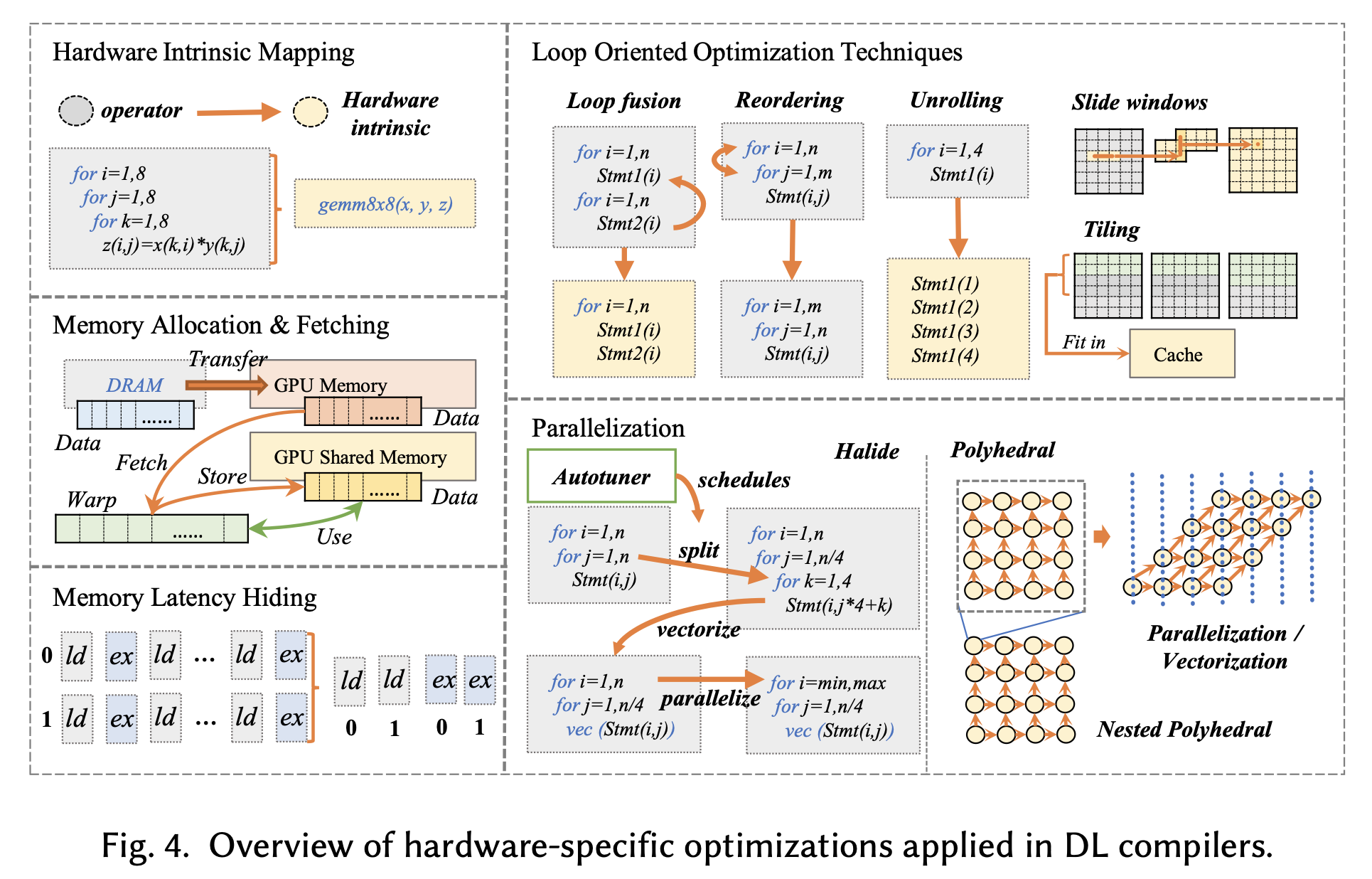
图 1 后端常用优化方法
MegCC
接下来就以 MegCC 为例概括介绍一下基于 MLIR 实现一个深度学习编译器,其关键就是如何根据需求定义一系列 IR,以及定义 Pass 将高级 IR lowering 到低级 IR,同时进行上述优化。
MegCC简介
MegCC 实现的原理是:深度学习模型在推理时候,每一个 Operator 都会对应一个计算 kernel 并完成计算,所以整个深度学习模型在推理时就是一次执行所有 Operator 的计算 kernel,执行完成之后就可以获得最终推理的结果。传统深度学习推理框架在运行时会做以下几件事情:
- 计算图优化 ----- 主要和模型相关。
- Kernel 选择 ----- 为模型的每个 Operator 根据参数选择合适的 Kernel 进行计算。
- 内存分配 ----- 由模型以及模型中每个 Operator 执行的 Kernel 决定内存分配的大小。
- 执行每个 Operator 的 Kernel ----- 和推理的数据强相关。
在上述传统深度学习推理需要完成的事情中,图优化,Kernel 选择,内存分配都是只和训练好的模型相关和推理时候的输入数据不相关,因此这些工作都可以放在模型编译时完成,运行时仅仅执行每一个 Operator 的 Kernel 就可以完成推理。MegCC 就是将上面图优化,Kernel 选择,内存分配都放在 MegCC 的编译阶段完成,将 Operator 的 Kernel 计算才放到 Runtime 中进行计算,这样有以下优势:
- Runtime 非常轻量,比起传统的推理框架小一个数量级,因为 Runtime 只包含了模型中所必须的 Kernel,不相关的不会被编译进去。
- 提升性能,因为 Runtime 只做 kernel 计算,所以避免了不必要的开销。
- Kernel 性能优化,因为每一个 Kernel 都是针对每一个 Operator 定制的,因此可以根据 Operator 的参数进行更加深入的优化。
- 解决 Operator fuse 之后的算子长尾问题,比如对 conv 之后融合的 activation 的种类和数量没有限制,可以支持更多的 fuse,也不造成 Runtime 的大小有明显的改变。
- 另外 MegCC 的 runtime 使用纯 C 实现,可以轻松移植到其他的嵌入式芯片中。
MegCC 主要包含两部分,一部分是 compiler 部分,另外一部分是 runtime 部分,下面重点介绍与编译相关的 compiler 部分。
MegCC compiler
Compiler 主要流程是:
- 依赖 MegEngine (我司开源深度学习框架)进行模型的导入和静态图优化(block-level optimizations,算子融合等)。
- 将优化后的模型转换为基于 mlir 自定义的 MGB IR。
- MGB IR 经过一系列 pass 经过 Abstract Kernel IR 最终转换到 Kernel IR。
- 将 Kernel IR 导出为 runtime model 和 runtime kernel,供 MegCC 的 runtime 部分使用。
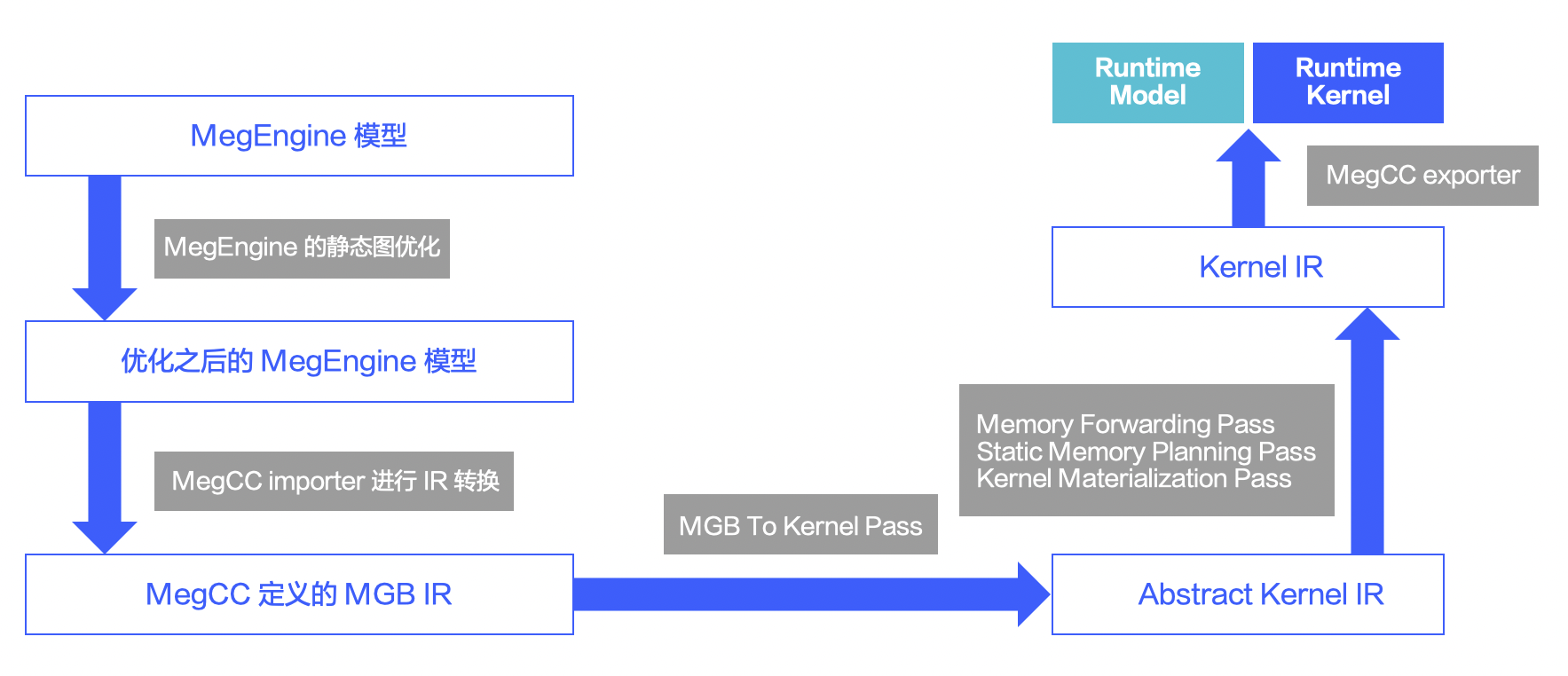
图 2 MegCC compiler 流程
MegCC 中的 IR
MegCC 基于 MLIR 定义了一系列的 IR。MLIR 的 IR 定义需要用户定义 Dialect(详见官方文档),然后由 TableGen 在程序编译阶段转换成 C++ 表示。
- MGB IR:定义为和 MegEngine 中 Operator 一一对应,是 MegCC 导入进 mlir 系统的入口 IR,它包含了每个 Opr 的类型以及这个 Opr 对应的参数,其每一个输入输出变量都是 Tensor,并且是单赋值(SSA)的。详见 GitHub MegCC MGB IR。
- Abstract Kernel IR:抽象 Kernel 层 IR,主要上面 MGB IR 通过转换之后得到,该 IR 中的输入输出已经 lowering 到 Buffer 了,因此不再是 SSA,另外 Opr 的属性也由 MegEngine 中定义的枚举值,转变成为了字符串。详见 GitHub MegCC Abstract Kernel IR。
- Kernel IR:表示已经生成 Kernel 之后的IR形式,其已经没有 Opr 的概念,整个计算图通过一个个对应的 Kernel 链接在一起,Opr 的参数等都固化在了定义好的 Kernel 中。详见 GitHub MegCC Kernel IR。
MegCC 中主要的 Pass
- MGBToKernelPass:这个 Pass 主要将 MGB IR 转换为 Abstract Kernel IR,转换过程中主要完成几件事情:
- 将 MGB IR 中的所有输入输出 Tensor 类型转换为 Buffer 类型。
- 将 MGB IR 中的所有枚举参数转换为对应的字符,这样 Abstract Kernel IR 就可以完全和 MegEngine 解耦。
- 将一些内存搬运相关的 Opr 全部转换为 Relayout,如:Concat,SetSubtensor 等 Opr(node-level optimizations)。
- 将判断 Opr 是静态 shape 还是动态 shape,动态 shape 就是输入 tensor 的 shape 需要依赖输入的值才能计算出来的,如:输出一个 tensor 中所有大于 1 的数。如果是静态 shape 直接转换到 Abstract Kernel IR,如果是动态 shape 直接转换到 Kernel IR 的 Instruction 中。
- MGBFuseKernelPass:应用在 MGB IR 上,基于 mlir 的模板匹配的方法尽可能的完成 kernel 的融合,比如连续两个 typecvt 合并成为一个 typecvt 等(block-level optimizations,算子融合)。
- MemoryForwardingPass:将遍历 Abstract Kernel IR 所有可能不用计算,直接 share 输入内存的 Opr,如果这些 Opr 确实不用计算,则直接 forward memory,如果这些 Opr 需要进行内存搬运,则会用 Relayout Opr 替换原来的 Opr(node-level optimizations)。
- KernelMaterializationPass:将所有 Abstract Kernel IR 都装载上真正 Kernel code 并转化为 KernelCall,然后添加对应的 KernelDef。KernelCall 和 KernelDef 之间通过 symbol 进行匹配。
- StaticMemoryPlanningPass:将所有静态 shape 的 memref 进行内存规划,内存规划算法使用改进的 MegEngine 的内存规划算法–PushDown 算法,能够极大程度的压缩运行时内存使用量。同时将 mlir 的 memref.Alloc 替换为 Kernel IR 的 MemPlan,MemPlan 中主要记录了内存规划的一整块 memref 以及该 Tensor 在规划的内存中的偏移量(dataflow-level optimizations,静态内存规划)。
上面的 Pass 就完成模型的图优化、内存规划以及 Kernel 生成,上文提到的后端优化即在 Kernel 生成阶段体现,目前 MegCC 主要使用人工优化的 Kernel 模版。最终可以根据 Runtime 中定义的模型格式 dump 编译之后的模型,以及生成计算模型所需的 Kernel 文件。 下面以一个简单的模型为例,使用 MegCC 的辅助工具(下载 Release 包) mgb-importer 和 megcc-opt,观察经过各个 Pass 的处理 IR 的变化。也可使用 mgb-to-tinynn 工具直接完成模型的编译过程,详见 MegCC 入门文档。
- dump 模型(使用 megengine)
import megengine.functional as F
import megengine.module as M
import megengine.optimizer as optim
from megengine import jit
import megengine
import numpy as np
class MulAddNet(M.Module):
def __init__(self):
super().__init__()
def forward(self, input):
x = input * 2.
x = x + 1.5
return x
model = MulAddNet()
model.eval()
@jit.trace(symbolic=True, capture_as_const=True)
def infer_func(data, *, model):
pred = model(data)
return pred
data = megengine.Tensor([[1., 2.], [3., 4.]])
output = infer_func(data, model=model)
print(output)
infer_func.dump("MulAdd.mge", arg_names=["data"])
```
- importer 模型到 MGB IR
./bin/mgb-importer MulAdd.mge mulAdd.mlir
cat mulAdd.mlir
output:
module {
"MGB.ParamStorage"() {sym_name = "const<2>[2]", sym_visibility = "private", type = tensor<1xf32>, user_count = 1 : i32, value = dense<2.000000e+00> : tensor<1xf32>} : () -> ()
"MGB.ParamStorage"() {sym_name = "const<1.5>[4]", sym_visibility = "private", type = tensor<1xf32>, user_count = 1 : i32, value = dense<1.500000e+00> : tensor<1xf32>} : () -> ()
func @mulAdd(%arg0: tensor<2x2xf32> {mgb.func_arg_name = "data"}) -> (tensor<2x2xf32> {mgb.func_result_name = "FUSE_MUL_ADD3(const<2>[2],data,const<1.5>[4])[14]"}) {
%0 = "MGB.Reshape"(%arg0) {axis = 7 : i32} : (tensor<2x2xf32>) -> tensor<2x2xf32>
%1 = "MGB.ParamProvider"() {name = @"const<1.5>[4]"} : () -> tensor<1xf32>
%2 = "MGB.ParamProvider"() {name = @"const<2>[2]"} : () -> tensor<1xf32>
%3 = "MGB.Elemwise"(%2, %0, %1) {mode = 35 : i32} : (tensor<1xf32>, tensor<2x2xf32>, tensor<1xf32>) -> tensor<2x2xf32>
return %3 : tensor<2x2xf32>
}
}
可以看到,在 importer 的过程中,乘法运算和加法运算被融合成了"FUSE_MUL_ADD3"。
- MGBToKernelPass、MemoryForwardingPass 和 StaticMemoryPlanningPass
./bin/megcc-opt --MGB-to-Kernel --memory-forwarding --static-memory-planning mulAdd.mlir > mulAdd_final.mlir
cat mulAdd_final.mlir
output:
#map = affine_map<(d0, d1) -> (d0 * 2 + d1)>
module {
"Kernel.WeightStorage"() {sym_name = "const<2>[2]", type = tensor<1xf32>, user_count = 1 : i32, value = dense<2.000000e+00> : tensor<1xf32>} : () -> ()
"Kernel.WeightStorage"() {sym_name = "const<1.5>[4]", type = tensor<1xf32>, user_count = 1 : i32, value = dense<1.500000e+00> : tensor<1xf32>} : () -> ()
func @mulAdd(%arg0: memref<2x2xf32> {mgb.func_arg_name = "data"}, %arg1: memref<16xi8> {mgb.func_arg_name = "kGlobalBuffer"}) -> (memref<2x2xf32, #map> {mgb.func_result_name = "FUSE_MUL_ADD3(const<2>[2],data,const<1.5>[4])[14]"}) {
%0 = "Kernel.Reshape"(%arg0) {axis = 7 : i32, determined = true} : (memref<2x2xf32>) -> memref<2x2xf32, #map>
%1 = "Kernel.GetWeight"() {name = @"const<1.5>[4]"} : () -> memref<1xf32>
%2 = "Kernel.GetWeight"() {name = @"const<2>[2]"} : () -> memref<1xf32>
%3 = "Kernel.MemPlan"(%arg1) : (memref<16xi8>) -> memref<2x2xf32, #map>
"Kernel.FUSE_MUL_ADD3"(%2, %0, %1, %3) : (memref<1xf32>, memref<2x2xf32, #map>, memref<1xf32>, memref<2x2xf32, #map>) -> ()
return %3 : memref<2x2xf32, #map>
}
}
经过上面几个 Pass,MGB IR 被转换为了 Kernel IR 并进行了内存规划。感兴趣的话可以更细粒度地看每个 Pass 做的事情,使用 megcc-opt 的参数控制使用哪些 Pass。
Kernel 生成
MegCC Compiler 会为模型中的每个 Operator 生成一个对应的 Kernel 来完成计算。 目前 MegCC 中大多数 Kernel 为人工优化并提前写好的 Kernel 模板,这些模板会根据具体的 Operator 参数生成对应的 Kernel。大多数为人工优化的 Kernel 的原因是:目前在 CPU 上不搜参的情况下,mlir 生成的 Kernel 性能和手写的 Kernel 还有一定的距离,但是自动生成 Kernel 的方法长期来看是比较可取的。
MegCC 现已开源,仓库地址:https://github.com/MegEngine/MegCC,欢迎试用、star、issue。
附:
更多 MegEngine 信息获取,您可以:查看文档、和 GitHub 项目,或加入 MegEngine 用户交流 QQ 群:1029741705。欢迎参与 MegEngine 社区贡献,成为 Awesome MegEngineer,荣誉证书、定制礼品享不停。
参考文献:
The Deep Learning Compiler: A Comprehensive Survey. MINGZHEN LI, YI LIU, etc. 2020. ↩︎

上一篇: 分享
BaseDet: 走过开发的弯路

下一篇: 分享
一个深度学习框架的年度报告
 相关推荐
相关推荐编译器上手指南,算子开发及开源项目指导手册,直播报名通道限时开启!
2023/12/07
开源项目分享,实习宝典传授,直播课程报名开启
2023/08/25
MegEngine 使用小技巧:如何解读 MegCC 编译模型几个阶段 Pass 的作用
2023/05/30
CPU 程序性能优化
2023/11/16
MegEngine 使用小技巧:如何使用 MegCC 进行模型编译
2023/07/06

