


博客
作者:旷视 MegEngine 架构师 张孝斌
快速了解 mperf
在移动/嵌入式平台,为了最大程度发挥硬件算力,对算子极致性能的追求变成必然,不同于桌面/服务器平台,移动/嵌入式平台在算子性能调优方面可选择的工具很少。
MegEngine 团队一直在探索什么样的工具能够在算子调优流程中带来助益,来帮助达成如下的算子性能调优反馈回路,这也是 mperf 诞生的背景。
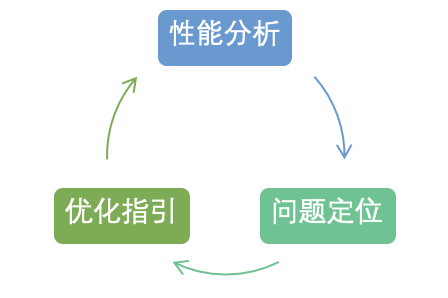
图1 算子性能调优反馈回路
mperf 是一个微架构层次的算子性能调优工具箱,主要面向移动/嵌入式平台的 CPU/GPU 核心,目标是“为构建一个更接近闭环的算子调优反馈回路”提供系列基础工具。
核心功能:
-
[基础能力] 测试微架构层次的各类常用性能分析参数(GFLOPS/Multi-level Bandwidth/Latency…)
-
[基础能力] 提供 PMU(Performance Monitoring Unit) 数据获取能力
-
[性能分析] 绘制 Hierarchical Roofline
-
[问题定位] 加工 PMU 数据得到各种指标(如 IPC, Instructions per cycle)、TMA(Top-Down Microarchitecture Analysis Method)分析能力,可以作为部分 vendor 提供的 GUI 分析工具的平替
-
[优化指引] 提供 OpenCL Linter 方案(后续版本提供)
-
…
作为一个 C++ API 级别的工程,mperf 外部依赖少,可以简单方便(侵入式)集成到目标工程中,目前已经开源到 GitHub,欢迎大家试用交流。
使用方法参考 README 文档;快速上手指南见 Tutorial 文档
对 mperf 的实现原理感兴趣的同学,可以继续往下看~~
展开说说 mperf 的工程实现
缘起
算子调优目前还是一个难以闭环的工作,需要开发者对目标硬件架构特性、算子优化水平评估、性能瓶颈定位、丰富的优化技巧等都有很深的了解之后才能变得游刃有余。同时随着 CPU/GPU 架构越来越多,越来越复杂,普通的开发者很少有精力去深入理解各个架构的特性,问题变得更加棘手。
理想中的调优过程是能够形成如上图所示的闭环,甚至可以走向编译器全自动化调优方案,过程中往往需要依赖工具完成,在桌面/服务器平台的工具较为完备,如 linux perf, lmbench/stream,NVIDIA NSight Compute,Intel vtune/Advisor/pmu-tools 等开闭源工具等都提供了一部分能力,通过人为组合还是能得到比较全的能力;与此同时,在移动/嵌入式平台,也有 simpleperf、Arm mali streamline、snapdragon profiler、MegPeak、ArchProbe、HWCPipe 等优秀的开闭源工具,但是完备性和易用性方面都存在很多问题:
-
GUI 工具不支持函数级/代码片段分析(如基于 PMU 的指标分析等,详见下方“PMU 数据搜集、加工和分析”),还不容易扩展新的分析指标
-
不支持 ARM CPU 的 TMA 分析(详见下方“PMU 数据搜集、加工和分析”)
-
绘制 Roofline 等所依赖的基础数据的获取能力散落在多个工具中,普通同学很难入手
-
很少的优化指导能力
因此我们启动了 mperf 项目,希望提供系列工具来完整获得这些基础能力:
-
常见 CPU/GPU 微架构参数,目前已经支持 ARM CPU/Mali GPU/ Adreno GPU 的部分型号
-
通过 Hierarchical Roofline 模型评估算子优化水平
-
通过丰富的指标和 TMA 分析模型来定位性能瓶颈/提示性能问题
-
通过 OpenCL Linter 等工具能固化专家优化经验,扫描用户代码后给出性能优化建议
-
…
常见 CPU/GPU 微架构参数
为 Roofline 绘制/Metrics (指标)计算等模块提供架构相关的基础参数,如多级存储 bandwidth/latency,指令 throughput/latency,各种基础 micro-kernel的bandwidth,GPU 特有的参数(warp size 等)等,这部分是常规功能,测试原理很多都参考了 MegPeak/lmbench/ArchProbe 等工程的实现,此处不再展开,仅举一个小例子方便大家看到它的价值。
例1. 在移动端 GPU 上在做向量计算的时候,我们会关心 int8:int16:int32 算力是否一定存在 4:2:1 的关系?mperf 实测数据显示在 Adreno A640 呈现难以解释的 int16>int8>int32,在 Mali G78 上则满足比例关系,实测的详实数据会告知开发者 float->int16 定点化是否能带来性能收益。
Hierarchical Roofline 绘制
原生 Roofline Model 建模了“算子计算模式、目标硬件架构、性能”三者之间的关系,可以为算子调优提供大方向的指引,比如:
-
确认瓶颈:位于 Machine Balance Point 左侧是访存 bound,右侧是计算 bound
-
指导优化方向: 如果是访存 bound,可以考虑结合各种已知的专家经验如 tiling/prefetch/aligned allocator 等进行优化尝试,也就是知道了努力的方向
-
提示停止优化的时机:如果是计算 bound 且已经接近屋顶(峰值性能上限),可以考虑停止优化
-
预测性能:如果已知架构峰值性能数据、算子本身的计算访存比、计算规模这三个数据就能算估算出执行时间
但因为原生 Roofline Model 存在一些问题:
-
未区分多级存储的情况,一般只考虑 DRAM Bandwidth,如果输入 Tensor 小到可以塞入 L1 Cache,采用 L1 Cache Bandwidth 更加准确
-
未区分执行环境的复杂性,比如是否启动多线程,处于 Turbo Mode 等,这些都影响实际理论峰值
-
未区分指令类型(instruction mixes),一般默认采用单一指令如 FMA 进行测试,实际理论峰值可以是不同指令性能的加权求和
-
未区分 read/write/access,比如 sum(Tensor),采用 read Bandwidth 更加准确
之后发展出了 Hierarchical Roofline,实际中为了方便绘制,mperf 提供了不同的手段来获取上述基础数据。
绘制Roofline需要两组数据:
-
架构理论峰值性能(GFLOPS)和带宽(Bandwidth)
- 理论峰值性能:单指令测试原理参考此文;分析不同指令占比的方案还在验证中;
- 理论带宽: 提供的方案可以测试多级存储带宽,并提供各种基础 micro-kernel (如纯 read 函数)来测试贴近实际访存模式的带宽上限
-
算子实测性能/带宽: 通过 PMU 的方式获取
PMU 数据搜集、加工和分析
PMU 数据搜集
CPU/GPU 架构大多都包含 PMU 硬件,用于计数一些底层硬件事件,如 CPU Core 所属的执行指令数和时钟周期,Cache 所属的 L1 Cache Miss 等;mperf 提供了 CPU/GPU 的 PMU 数据获取能力,特别是 Adreno GPU 这种缺乏官方开源支持的平台。
加工指标(又名 Metrics)
以 ARM A55 Core 为例,有超过 100 种硬件事件,Adreno A6xx 系列 GPU 则有约 125 种硬件事件,这些事件的数值可以用来加工计算各种指标,如 IPC=INST_RETIRED 计数(指令数)/ CPU_CYCLES 计数(Cycle 数),也可以用来计算 DRAM Bandwidth、算子 GFLOPS、L1 MISS Ratio 等等,具体的指标支持列表及其计算方式可阅读文档及源码。
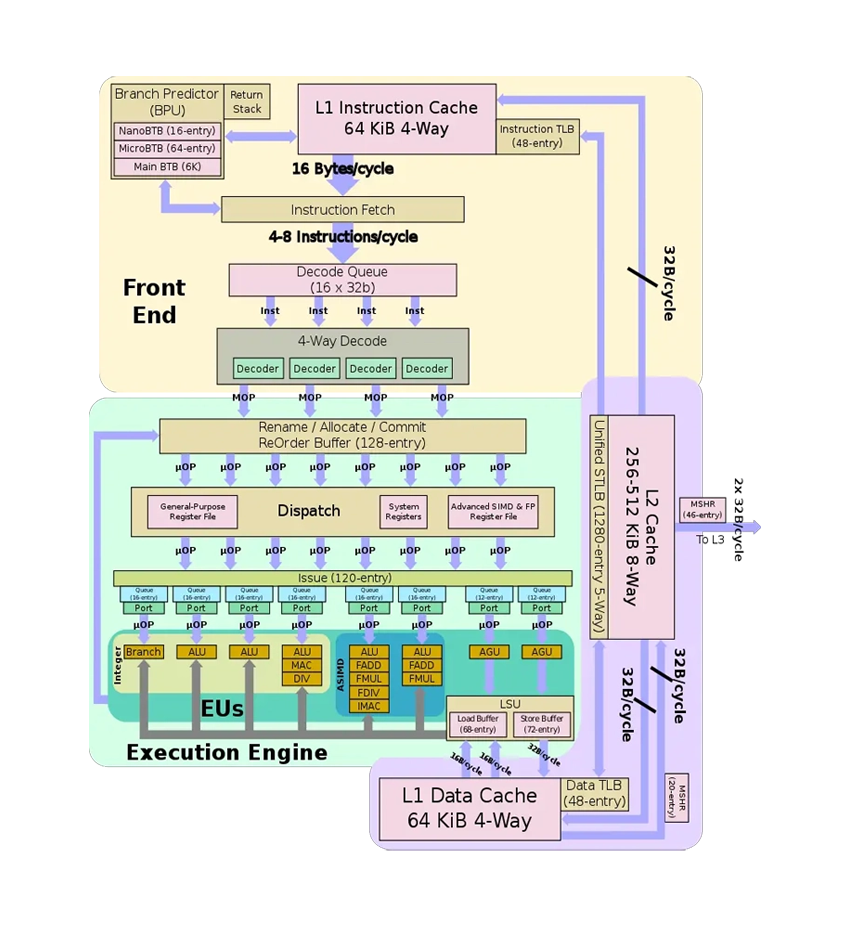
图2 Arm A76 Core 微架构图(来源)
TMA 分析
TMA 是一套自顶向下的 Intel CPU 算子性能瓶颈分析方法,这套思想可以扩展到其它架构。上图描述了 A76 Core 指令的生命周期,过程中涉及到的硬件资源(如可执行 FMA 的端口数量)都可能成为指令执行过程中的瓶颈,TMA 用于分析瓶颈所在,从而指引优化方向,详细思想大家可以阅读官方文档。
mperf 计算得到的所有指标中一部分可以归类进 TMA 范式,另一部分作为单独的指标存在用于辅助性能分析。不管是 TMA 还是独立指标都可以提供细粒度的优化方向指引。
在 mperf 里面我们将 TMA 扩展到了 ARM CPU 上,过程中我们得到了一些经验:
-
因为 ARM CPU 提供的硬件事件的类别/定义与 Intel CPU 有很多差异,完美复刻 TMA 各类别的定义很困难也不现实,但是 ARM CPU 本身提供的硬件事件的类别也很丰富,可以摸索和总结出适合自身的 TMA 方案和独立指标,实践中我们证明了这条路行的通。
-
ARM 不同系列 CPU 微架构之间有明显差异,比如 A55(in-order)与 A76(out-of-order)在 TMA 各类别/定义上有很多不同,每个架构都需要单独处理。
-
由于 vendor 相关资料开放程度不同,部分指标的定义可能会在长期实践验证中被修正。
本模块 GPU 部分的长期目标是成长为移动端 GPU 类似 NVIDIA Nsight Compute 的等价物。目前已经总结了很多有优化指导意义的 GPU 指标,但 TMA 在 GPU 上可行性和必要性我们还在探索中。在通用计算相关指标方面(不涉及渲染相关),目前已经具备替代 ARM 官方 GUI 工具 streamline 和高通官方 GUI 工具 snapdragon profiler 的能力,使用这两个 GUI 工具的同学可以尝试替换为 mperf,一方面 API 级别更加灵活,另一方面可以享受到不断增补指标(Metrics)带来的好处。
这里同样举一个实际例子来展示 mperf 的工作逻辑:
例2:GPU 支持不同向量宽度的浮点数据加载,如 vload4/8/16 等等,不同的架构有不同的限制,并不是向量宽度越宽越好,我们观察到 Mali G78 GPU 上 vload4 比 vload16 快很多,在 mperf 中的分析逻辑如下:
首先搜集一系列 event 的数值(下图 3 展示了其中一部分),如 ExternalMemoryReadBytes 含义是 DDR→Unified L2 Cache 的 read 数据量,可以看出 vload16 相对 vload4 增加了 4 倍还多, LoadStoreReadFull(LS_MEM_READ_FULL) 含义是 full-width read 的次数,LoadStorePartial(LS_MEM_READ_SHORT)代表了 partial-width read 的次数,发现在 vload16 的时候 partial-width read 的次数增大了很多,额外发射了更多的 read 指令,解释了速度变慢的原因。为了方便快速发现此类问题,mperf 也专门整理了一个 PartialReadRatio 的指标,其计算公式见下方。
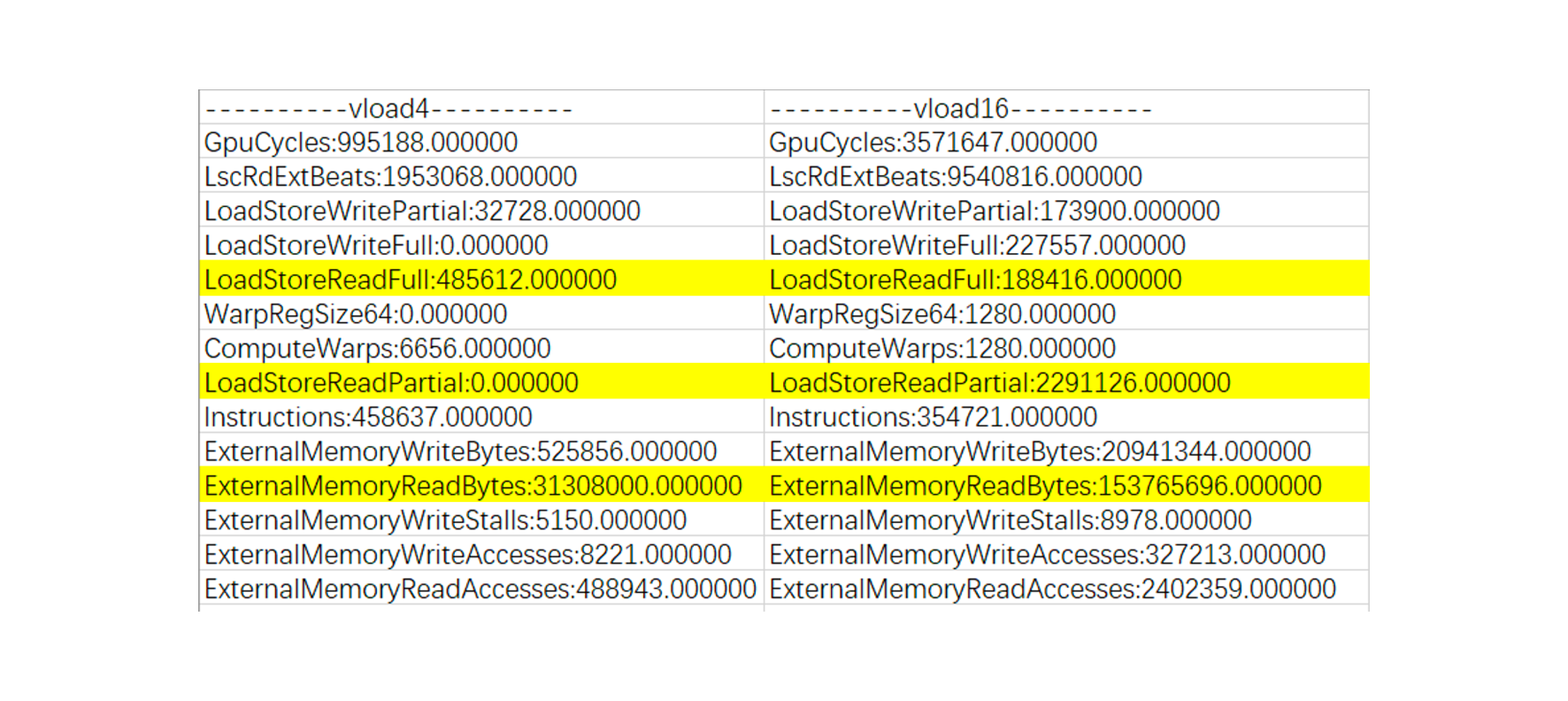
图3 Mali G78 vload4/vload8
// PartialReadRatio 计算公式
GpuCounter::PartialReadRatio, [this] {
return get_counter_value(MALI_NAME_BLOCK_SHADER, "LS_MEM_READ_SHORT") /
(float)(get_counter_value(MALI_NAME_BLOCK_SHADER,"LS_MEM_READ_FULL") + get_counter_value(MALI_NAME_BLOCK_SHADER, "LS_MEM_READ_SHORT"));}
更多关于 PMU 数据搜集、加工和分析的细节,欢迎大家阅读源码。
OpenCL Linter
MegEngine 团队在做 OpenCL 算子开发的过程中积累了一系列优化经验,希望能通过工具化的方式将这部分经验固化下来。
目前初步计划参考 Linter 思路,大体有两个部分:
-
静态代码分析扫描 OpenCL Kernel,检查规则是预置的 OpenCL 专家优化经验,如使用 select 指令而非三目运算符,对齐检查等,给出优化建议。
-
在动态执行过程中监测各种预置的指标,结合专家经验对一些异常数据给出提示,如寄存器使用量分析等,引导用户调优。
这部分工作目前正在做 POC 验证,敬请期待。
总结
mperf 为移动/嵌入式平台性能调优提供了系列工具,其中在 PMU 获取/ARM TMA/分层 Roofline 绘制/OpenCL Linter 等方面都有不同程度的创新,希望这个工具箱能为开发人员提供更多的分析手段和调优建议。
当前阶段 mperf 开发方向会以优先丰富基础工具为主,部分工具暂时还需要一些体系结构的知识才能用好,更长远来看,我们会做更多的工作来降低使用门槛,朝着更易用更自动化的方向努力。与此同时,大家都希望有一套闭环的方法论来告诉我们算子调优的时候每一步先分析什么指标,然后建议尝试 N 种优化方法,不断迭代到最优,但是目前业内距离这个愿景还有点远,mperf 也是如此,它的主要能力此刻还停留在为开发者提供更多决策信息的阶段。
为了能更近一步,下一阶段我们会先从积累丰富的实操案例入手,和 mperf 的使用者一起探索在不同的案例下什么样的指标能发现问题,什么样的优化方法可以尝试;之后在发现特定指标异常的时候可以将积累的优化方法展示给用户。因此,mperf 是一个具有成长性的工程,欢迎大家一起参与共建,聚沙成塔,打造好用的调优工具!
mperf 开发过程中受到了上面提到的各种优秀开源工程的启发和指引,方法论上参考了大量包括 Intel/ARM 官方文档在内的诸多资料,在此一并致谢!
附:
更多 MegEngine 信息获取,您可以:查看文档和 GitHub 项目,或加入 MegEngine 用户交流 QQ 群:1029741705。欢迎参与 MegEngine 社区贡献,成为 Awesome MegEngineer,荣誉证书、定制礼品享不停。

上一篇: 分享
MegEngine 使用小技巧:使用 Netron 实现模型可视化

下一篇: 分享
MegEngine 使用小技巧:借助 DataLoader 获取分批数据
 相关推荐
相关推荐MegEngine 使用小技巧:Profiler 使用手册
2023/08/30
借助 mperf 进行矩阵乘法极致优化
2023/03/27
MegEngine dataloader 新工具帮助定位性能瓶颈,快来体验吧!
2023/12/19
CPU 程序性能优化
2023/11/16
MegEngine 使用小技巧:如何做 MegCC 的模型性能评测
2023/06/14

