量化¶
量化指的是将浮点数模型(一般是 32 位浮点数)的权重或激活值用位数更少的数值类型 (比如 8 位整数、16 位浮点数)来近似表示的过程。 量化后的模型会占用更小的存储空间,还能够利用许多硬件平台上的专属算子进行提速。 比如在 MegEngine 中使用 8 位整数来进行量化,相比默认的 32 位浮点数, 模型大小可以减少为 1/4,而运行在特定的设备上其计算速度也能提升为 2-4 倍。
量化的目的是为了追求极致的推理计算速度,为此舍弃了数值表示的精度,直觉上会带来较大的模型掉点, 但是在使用一系列精细的量化处理之后,其掉点可以变得微乎其微,并能支持正常的部署使用。 而且近年来随着专用神经网络加速芯片的兴起,低比特非浮点的运算方式越来越普及, 因此如何把一个 GPU 上训练的浮点数模型转化为低比特的量化模型,就成为了工业界非常关心的话题。
一般来说,得到量化模型的转换过程按代价从低到高可以分为以下 4 种:
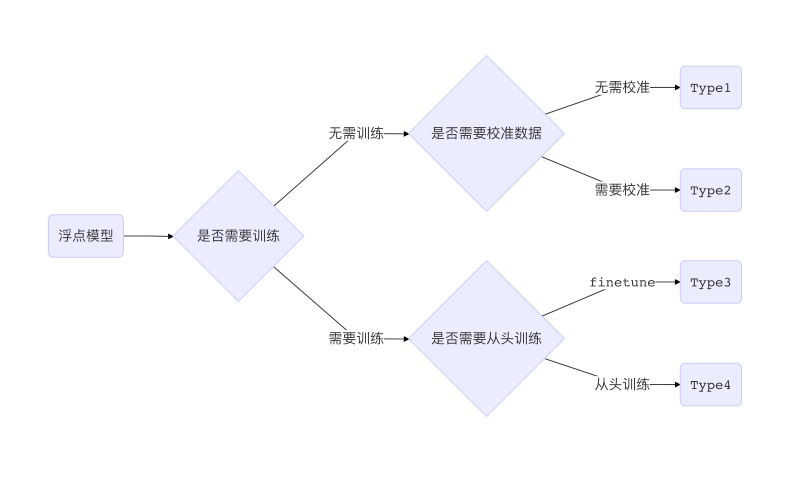
Type1 和 Type2 由于是在模型浮点模型训练之后介入,无需大量训练数据, 故而转换代价更低,被称为后量化(Post Quantization);
Type3 和 Type4 则需要在浮点模型训练时就插入一些假量化(FakeQuantize)算子, 模拟计算过程中数值截断后精度降低的情形,故而称为量化感知训练(Quantization Aware Training, QAT)。
本文主要介绍 Type2 和 Type3 在 MegEngine 中的完整流程。 事实上,除了 Type2 无需进行假量化,两者的整体流程完全一致。
整体流程¶
以 Type3 为例,一般以一个训练完毕的浮点模型为起点,称为 Float 模型。 包含假量化算子的用浮点操作来模拟量化过程的新模型,我们称之为 Quantized-Float 模型,或者 QFloat 模型。 可以直接在终端设备上运行的模型,称之为 Quantized 模型,简称 Q 模型。
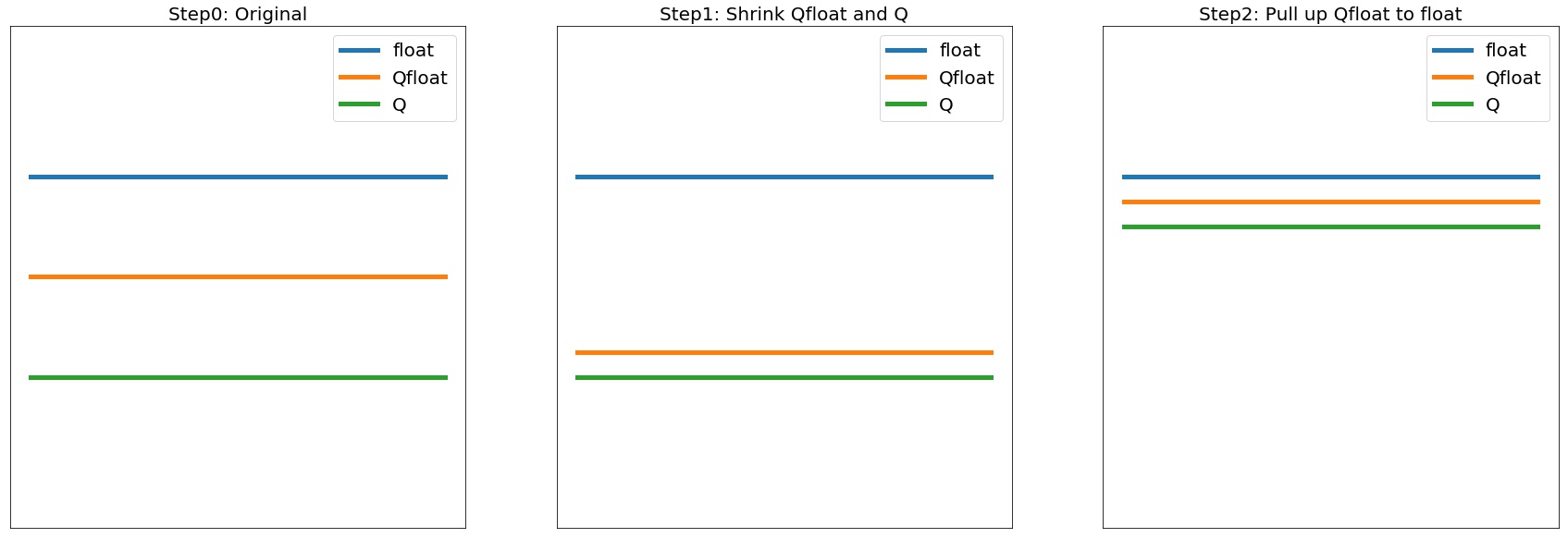
而三者的精度一般是 Float > QFloat > Q ,故而一般量化算法也就分为两步:
拉近 QFloat 和 Q,这样训练阶段的精度可以作为最终 Q 精度的代理指标,这一阶段偏工程;
拔高 QFloat 逼近 Float,这样就可以将量化模型性能尽可能恢复到 Float 的精度,这一阶段偏算法。
典型的三种模型在三个阶段的精度变化如下:
对应到具体的 MegEngine 接口中,三阶段如下:
基于
Module搭建网络模型,并按照正常的浮点模型方式进行训练;使用
quantize_qat将浮点模型转换为 QFloat 模型, 其中可被量化的关键 Module 会被转换为QATModule, 并基于量化配置QConfig设置好假量化算子和数值统计方式;使用
quantize将 QFloat 模型转换为 Q 模型, 对应的 QATModule 则会被转换为QuantizedModule, 此时网络无法再进行训练,网络中的算子都会转换为低比特计算方式,即可用于部署了。
该流程是 Type3 对应 QAT 的步骤,Type2 对应的后量化则需使用不同 QConfig, 且需使用 evaluation 模式运行 QFloat 模型,而非训练模式。更多细节可以继续阅读下一节详细的接口介绍。
接口介绍¶
在 MegEngine 中,最上层的接口是配置如何量化的 QConfig
和模型转换模块里的 quantize_qat 与 quantize 。
QConfig¶
QConfig 包括了 Observer 和 FakeQuantize 两部分。
我们知道,对模型转换为低比特量化模型一般分为两步:
一是统计待量化模型中参数和 activation 的数值范围(scale)和零点(zero_point),
二是根据 scale 和 zero_point 将模型转换成指定的数值类型。而为了统计这两个值,我们需要使用 Observer.
Observer 继承自 Module ,也会参与网络的前向传播,
但是其 forward 的返回值就是输入,所以不会影响网络的反向梯度传播。
其作用就是在前向时拿到输入的值,并统计其数值范围,并通过 get_qparams 来获取。
所以在搭建网络时把需要统计数值范围的的 Tensor 作为 Observer 的输入即可。
# forward of MinMaxObserver
def forward(self, x_orig):
if self.enabled:
# stop gradient
x = x_orig.detach()
# find max and min
self.min_val._reset(F.minimum(self.min_val, x.min()))
self.max_val._reset(F.maximum(self.max_val, x.max()))
return x_orig
另外如果只观察而不模拟量化会导致模型掉点,于是我们需要有 FakeQuantize 来根据 Observer 观察到的数值范围模拟量化时的截断,使得参数在训练时就能提前“适应“这种操作。 FakeQuantize 在前向时会根据传入的 scale 和 zero_point 对输入 Tensor 做模拟量化的操作, 即先做一遍数值转换再转换后的值还原成原类型,如下所示:
def fake_quant_tensor(inp: Tensor, qmin: int, qmax: int, q_dict: Dict) -> Tensor:
scale = q_dict["scale"]
zero_point = 0
if q_dict["mode"] == QuantMode.ASYMMERTIC:
zero_point = q_dict["zero_point"]
# Quant
oup = Round()(inp / scale) + zero_point
# Clip
oup = F.minimum(F.maximum(oup, qmin), qmax)
# Dequant
oup = (oup - zero_point) * scale
return oup
目前 MegEngine 支持对 weight/activation 两部分的量化,如下所示:
ema_fakequant_qconfig = QConfig(
weight_observer=partial(MinMaxObserver, dtype="qint8", narrow_range=True),
act_observer=partial(ExponentialMovingAverageObserver, dtype="qint8", narrow_range=False),
weight_fake_quant=partial(FakeQuantize, dtype="qint8", narrow_range=True),
act_fake_quant=partial(FakeQuantize, dtype="qint8", narrow_range=False),
)
这里使用了两种 Observer 来统计信息,而 FakeQuantize 使用了默认的算子。
如果是后量化,或者说 Calibration,由于无需进行 FakeQuantize,故而其 fake_quant 属性为 None 即可:
calibration_qconfig = QConfig(
weight_observer=partial(MinMaxObserver, dtype="qint8", narrow_range=True),
act_observer=partial(HistogramObserver, dtype="qint8", narrow_range=False),
weight_fake_quant=None,
act_fake_quant=None,
)
除了使用在 Qconfig 里提供的预设 QConfig,
也可以根据需要灵活选择 Observer 和 FakeQuantize 实现自己的 QConfig。目前提供的 Observer 包括:
MinMaxObserver, 使用最简单的算法统计 min/max,对见到的每批数据取 min/max 跟当前存的值比较并替换, 基于 min/max 得到 scale 和 zero_point;ExponentialMovingAverageObserver, 引入动量的概念,对每批数据的 min/max 与现有 min/max 的加权和跟现有值比较;HistogramObserver, 更加复杂的基于直方图分布的 min/max 统计算法,且在 forward 时持续更新该分布, 并根据该分布计算得到 scale 和 zero_point。
对于 FakeQuantize,目前还提供了 TQT 算子,
另外还可以继承 _FakeQuant 基类实现自定义的假量化算子。
在实际使用过程中,可能需要在训练时让 Observer 统计并更新参数,但是在推理时则停止更新。
Observer 和 FakeQuantize 都支持 enable
和 disable 功能,
且 Observer 会在 train
和 eval 时自动分别调用 enable/disable。
所以一般在 Calibration 时,会先执行 net.eval() 保证网络的参数不被更新,
然后再执行 :enable_observer(net) 来手动开启 Observer 的统计修改功能。
模型转换模块与相关基类¶
QConfig 提供了一系列如何对模型做量化的接口,而要使用这些接口,
需要网络的 Module 能够在 forward 时给参数、activation 加上 Observer 和进行 FakeQuantize.
转换模块的作用就是将模型中的普通 Module 替换为支持这一系列操作的 QATModule ,
并能支持进一步替换成无法训练、专用于部署的 QuantizedModule 。
基于三种基类实现的 Module 是一一对应的关系,通过转换接口可以依次替换为不同实现的同名 Module。
同时考虑到量化与算子融合(Fuse)的高度关联,我们提供了一系列预先融合好的 Module,
比如 ConvRelu2d 、 ConvBn2d 和 ConvBnRelu2d 等。
除此之外还提供专用于量化的 QuantStub 、 DequantStub 等辅助模块。
转换的原理很简单,就是将父 Module 中可被量化(Quantable)的子 Module 替换为对应的新 Module. 但是有一些 Quantable Module 还包含 Quantable 子 Module,比如 ConvBn 就包含一个 Conv2d 和一个 BatchNorm2d, 转换过程并不会对这些子 Module 进一步转换,原因是父 Module 被替换之后, 其 forward 计算过程已经完全不同了,不会再依赖于这些子 Module。
注解
如果需要使一部分 Module 及其子 Module 保留 Float 状态,不进行转换,
可以使用 disable_quantize 来处理。
如果网络结构中涉及一些二元及以上的 ElementWise 操作符,比如加法乘法等,
由于多个输入各自的 scale 并不一致,必须使用量化专用的算子,并指定好输出的 scale.
实际使用中只需要把这些操作替换为 Elemwise 即可,
比如 self.add_relu = Elemwise("FUSE_ADD_RELU")
另外由于转换过程修改了原网络结构,模型保存与加载无法直接适用于转换后的网络, 读取新网络保存的参数时,需要先调用转换接口得到转换后的网络,才能用 load_state_dict 将参数进行加载。
实例讲解¶
下面我们以 ResNet18 为例来讲解量化的完整流程,完整代码见 MegEngine/Models . 主要分为以下几步:
修改网络结构,使用已经 Fuse 好的 ConvBn2d、ConvBnRelu2d、ElementWise 代替原先的 Module;
在正常模式下预训练模型,并在每轮迭代保存网络检查点;
调用
quantize_qat转换模型,并进行 finetune;调用
quantize转换为量化模型,并执行 dump 用于后续模型部署。
网络结构见 resnet.py ,相比惯常写法,我们修改了其中一些子 Module,
将原先单独的 conv, bn, relu 替换为 Fuse 过的 Quantable Module。
class BasicBlock(Module):
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv_bn_relu = ConvBnRelu2d(
in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False
)
self.conv_bn = ConvBn2d(
planes, planes, kernel_size=3, stride=1, padding=1, bias=False
)
self.add_relu = Elemwise("FUSE_ADD_RELU")
self.shortcut = Sequential()
if stride != 1 or in_planes != planes:
self.shortcut = Sequential(
ConvBn2d(in_planes, planes, kernel_size=1, stride=stride, bias=False)
)
def forward(self, x):
out = self.conv_bn_relu(x)
out = self.conv_bn(out)
cut = self.shortcut(x)
out = self.add_relu(out, cut)
return out
然后对该模型进行若干轮迭代训练,并保存检查点,这里省略细节:
for step in range(0, total_steps):
# Linear learning rate decay
epoch = step // steps_per_epoch
learning_rate = adjust_learning_rate(step, epoch)
image, label = next(train_queue)
image = tensor(image.astype("float32"))
label = tensor(label.astype("int32"))
n = image.shape[0]
loss, acc1, acc5 = train_func(image, label, net, gm)
optimizer.step()
optimizer.clear_grad()
再调用 quantize_qat 来将网络转换为 QATModule:
from ~.quantization import ema_fakequant_qconfig
from ~.quantization.quantize import quantize_qat
model = ResNet18()
if args.mode != "normal":
quantize_qat(model, ema_fakequant_qconfig)
这里使用默认的 ema_fakequant_qconfig 来进行 int8 量化。
然后我们继续使用上面相同的代码进行 finetune 训练。 值得注意的是,如果这两步全在一次程序运行中执行,那么训练的 trace 函数需要用不一样的, 因为模型的参数变化了,需要重新进行编译。 示例代码中则是采用在新的执行中读取检查点重新编译的方法。
在 QAT 模式训练完成后,我们继续保存检查点,执行 inference.py 并设置 mode 为 quantized ,
这里需要将原始 Float 模型转换为 QAT 模型之后再加载检查点。
from ~.quantization.quantize import quantize_qat
model = ResNet18()
if args.mode != "normal":
quantize_qat(model, ema_fakequant_qconfig)
if args.checkpoint:
logger.info("Load pretrained weights from %s", args.checkpoint)
ckpt = mge.load(args.checkpoint)
ckpt = ckpt["state_dict"] if "state_dict" in ckpt else ckpt
model.load_state_dict(ckpt, strict=False)
模型转换为量化模型包括以下几步:
from ~.quantization.quantize import quantize
# 定义trace函数,打开capture_as_const以进行dump
@jit.trace(capture_as_const=True)
def infer_func(processed_img):
model.eval()
logits = model(processed_img)
probs = F.softmax(logits)
return probs
# 执行模型转换
if args.mode == "quantized":
quantize(model)
# 准备数据
processed_img = transform.apply(image)[np.newaxis, :]
if args.mode == "normal":
processed_img = processed_img.astype("float32")
elif args.mode == "quantized":
processed_img = processed_img.astype("int8")
# 执行一遍evaluation
probs = infer_func(processed_img)
# 将模型 dump 导出
infer_func.dump(output_file, arg_names=["data"])
至此便得到了一个可用于部署的量化模型。