加载与预处理数据集¶
数据集是一组数据的集合,例如 MNIST、Cifar10 等图像数据集。
Dataset 是 MegEngine 中表示数据集的抽象类。
我们自定义的数据集类应该继承 Dataset 并重写下列方法:
__init__: 一般在其中实现读取数据源文件的功能。也可以添加任何其它的必要功能;__getitem__: 通过索引操作来获取数据集中某一个样本,使得可以通过 for 循环来遍历整个数据集;__len__: 返回数据集大小
自定义数据集¶
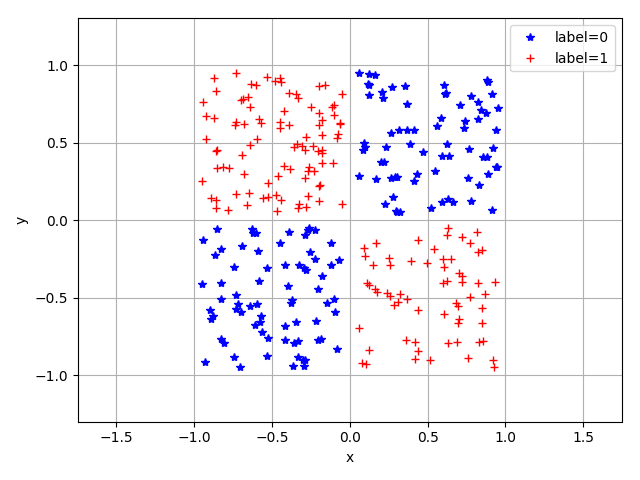
下面是一个简单示例。我们根据下图所示的二分类数据,创建一个 Dataset 。
每个数据是一个二维平面上的点,横坐标和纵坐标在 [-1, 1] 之间。共有两个类别标签(图中的蓝色 * 和红色 +),
标签为 0 的点处于一、三象限;标签为 1 的点处于二、四象限。
该数据集的创建过程如下:
在
__init__中利用 NumPy 随机生成 ndarray 作为数据;在
__getitem__中返回 ndarray 中的一个样本;在
__len__中返回整个数据集中样本的个数;
import numpy as np
from typing import Tuple
# 导入需要被继承的 Dataset 类
from megengine.data.dataset import Dataset
class XORDataset(Dataset):
def __init__(self, num_points):
"""
生成如图1所示的二分类数据集,数据集长度为 num_points
"""
super().__init__()
# 初始化一个维度为 (50000, 2) 的 NumPy 数组。
# 数组的每一行是一个横坐标和纵坐标都落在 [-1, 1] 区间的一个数据点 (x, y)
self.data = np.random.rand(num_points, 2).astype(np.float32) * 2 - 1
# 为上述 NumPy 数组构建标签。每一行的 (x, y) 如果符合 x*y < 0,则对应标签为1,反之,标签为0
self.label = np.zeros(num_points, dtype=np.int32)
for i in range(num_points):
self.label[i] = 1 if np.prod(self.data[i]) < 0 else 0
# 定义获取数据集中每个样本的方法
def __getitem__(self, index: int) -> Tuple:
return self.data[index], self.label[index]
# 定义返回数据集长度的方法
def __len__(self) -> int:
return len(self.data)
np.random.seed(2020)
# 构建一个包含 30000 个点的训练数据集
xor_train_dataset = XORDataset(30000)
print("The length of train dataset is: {}".format(len(xor_train_dataset)))
# 通过 for 遍历数据集中的每一个样本
for cor, tag in xor_train_dataset:
print("The first data point is: {}, {}".format(cor, tag))
break
print("The second data point is: {}".format(xor_train_dataset[1]))
输出:
The length of train dataset is: 30000
The first data point is: [0.97255366 0.74678389], 0
The second data point is: (array([ 0.01949105, -0.45632857]), 1)
MegEngine 中也提供了一些已经继承自 Dataset 的数据集类,方便我们使用,
比如 ArrayDataset ,允许通过传入单个或多个 NumPy 数组,对它进行初始化。
其内部实现如下:
_init__: 检查传入的多个 NumPy 数组的长度是否一致;不一致则无法成功创建;__getitem__: 将多个 NumPy 数组相同索引位置的元素构成一个 tuple 并返回;__len__: 返回数据集的大小;