Autodiff 高阶使用¶
v1.5 开始,MegEngine 提供了实验性的高阶微分支持,允许多个GradManager进行协作。使用场景介绍如下。 你可以利用这个特性, 实现高阶微分、前向微分和多个一阶微分
高阶微分¶
对于 GradManager 来说,它只关心并如实的记录在启用范围内的全部 Tensor 计算操作,并不会区分这个 Tensor 是通过 forward 计算得到还是另一个 GradManager 求导得到(即求导器可以对 x.grad 再次进行求导)。
通过嵌套两层 GradManager ,我们可以实现求二阶导的效果。
# 这里想求x.grad对 x 的梯度:grad(x, grad(x, y))
def test_2nd_grad_with_manager():
x_np = np.random.rand(10).astype("float32")
x = mge.tensor(x_np)
gm = GradManager().attach([x]) # 外层求导器,负责求二阶导
gm2 = GradManager().attach([x]) # 内层求导器,负责求一阶导
with gm: # gm 在 gm2外部,因此gm可以观测到gm2的backward行为
with gm2:
y = F.cos(x) # forward
gm2.backward(y) # backward,此时得到一阶导
x_grad = x.grad # 保存一阶导
x.grad = None # 将导数清空(否则后续会累计上来)
np.testing.assert_almost_equal( # 确认一阶导的正确性
x_grad.numpy(), -np.sin(x_np), decimal=5
)
gm.backward(x_grad) # 求一阶导 x_grad 对 x 的导数,即二阶导,结果会存储在 x.grad 上
np.testing.assert_almost_equal( # 确认二阶导的正确性
x.grad.numpy(), -np.cos(x_np), decimal=5
)
从外部gm的视角来看,它并不关心求导对象是在 backward 阶段产生还是从 forward 阶段产生的,只要是在 gm scope 内的计算都会被记录下来,如下图所示。
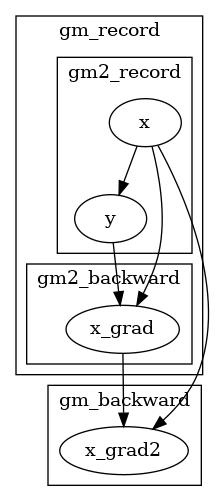
求二阶导时,需要注意嵌套顺序¶
我们调换 gm 与 gm2 的顺序,可以看到,在 gm.backward() 之后, x.grad 为空,也就是说 gm 没有求出 x 对 x.grad 的梯度。这是因为此时 gm 被放在内层,无法观测到 gm2.backward 这个行为。因此在 gm 眼里 x.grad 就好似凭空产生的(和 x.grad = Tensor(3) 一样),当然无法对其求导。
# expect grad(x, grad(x, y)), got None
def test_2nd_grad_fail_with_manager():
x_np = np.random.rand(10).astype("float32")
x = mge.tensor(x_np)
gm = GradManager().attach([x])
gm2 = GradManager().attach([x])
with gm2: # 注意此处
with gm: # 此时 gm 与 gm2 位置互换,放在内层
y = F.cos(x)
x_grad = gm2.backward(y)
x.grad = None
np.testing.assert_almost_equal(x_grad.numpy(), -np.sin(x_np), decimal=5)
gm.backward(x.grad)
assert x.grad is None
多次反向微分来模拟前向微分¶
# expect grad(oup_grad, grad(inp, oup, oup_grad))
def test_emulate_forward_mode_with_reverse_mode(target):
expr = F.cos
def jvp(inp, expr):
with GradManager() as gm: # 这里不知道输出的形状,只能推迟attach
with GradManager().attach([inp]) as gm2:
oup = expr(inp)
oup_grad = F.ones_like(oup) # 随便给一些值都行
gm.attach(oup_grad) # 等下要拿oup_grad.grad
gm2.backward(oup, oup_grad) # 算出对应的inp_grad,这里oup_grad参与了计算,等下可以求它的梯度
gm.backward(inp.grad) # 算出oup_grad.grad
return oup, oup_grad.grad
def numerical_jvp(inp, expr):
delta = 0.001
return expr(inp), (expr(inp + delta) - expr(inp - delta)) / (2 * delta) # 求出近似值
x_np = np.random.rand(10).astype("float32")
x = mge.tensor(x_np)
y, dy = jvp(x, target)
y1, dy1 = numerical_jvp(x, target)
np.testing.assert_almost_equal(y.numpy(), y1.numpy(), decimal=5)
np.testing.assert_almost_equal(dy.numpy(), dy1.numpy(), decimal=3)
求两个一阶导¶
如果你希望在一次计算中,分别对不同的一批参数求导,那么你可以使用 gm | gm2 的写法,可分别求两个一阶导。 和 with gm: with gm2 写法相比,可以在不求高阶导的形式下节省一点代码,此外这两种写法其实语义上有微妙的差别: gm | gm2 中两个求导器是平等的(没有内外层之分),自然也是相互不可见的,有时可以避免一些意料之外的行为。
# expect grad(x, y) + grad(x, y)
def test_2nd_grad_with_manager_union():
x_np = np.random.rand(10).astype("float32")
x = mge.tensor(x_np)
gm = GradManager().attach([x])
gm2 = GradManager().attach([x])
with gm | gm2: # 这里代表将gm与gm2取并,即同时挂上这两个求导器
y = F.cos(x)
gm.backward(y)
gm2.backward(y)
np.testing.assert_almost_equal(x.grad.numpy(), -2 * np.sin(x_np), decimal=5) # 得到双份导数(因为会累加),每个gm贡献一半
此时两个 GradManager 观测到的内容如下所示:
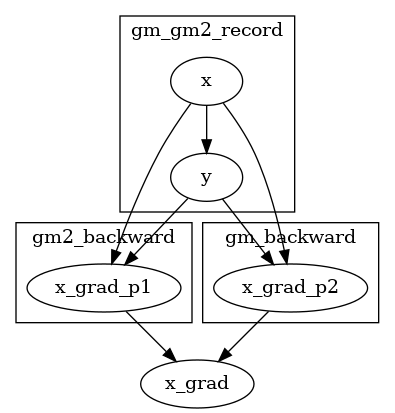
gm | gm2 中两个求导器是平等的(没有内外层之分),相互是不可见的。因此,在下面的代码中由于 gm2 对 gm 不可见,导致无法求出 x 对于 x_grad 的梯度。
# expect grad(x, grad(x, y)), got None
def test_2nd_grad_fail_with_manager_union():
x_np = np.random.rand(10).astype("float32")
x = mge.tensor(x_np)
gm = GradManager().attach([x])
gm2 = GradManager().attach([x])
with gm | gm2: #gm与gm2是同级的,并且互不可见
y = F.cos(x)
gm2.backward(y)
x_grad = gm2.backward(y)
x.grad = None
np.testing.assert_almost_equal(x_grad.numpy(), -np.sin(x_np), decimal=5)
gm.backward(x_grad)
assert x.grad is None