MegEngine 模型推理部署教程¶
警告
这套教程正处于缓慢发布状态,你看到的非最终成品,欢迎参与讨论改进。
适用人群 & 前置知识要求
本套教程适合那些想要知道 “如何将深度学习模型部署到生产环境中” 的开发者:
也许你刚学习完 《 MegEngine 深度学习入门教程 》,已经能够开发出一些简单的模型了, 但对如何将模型部署到不同的平台和设备十分好奇,想要尝试一些具体的实践,这套教程将带你入门;
如果你完全不关注模型开发的过程和细节,希望故事从已经拿到一个训练好的模型开始讲起。 不妨先试试看阅读用户指南中的 模型部署总览与流程建议 并进行实践,感到吃力的话再来阅读本系列教程。
你需要具备一定的 Python 开发经验,进阶主题中我们将会用到 C++ 与源码编译,以追求极致的性能。
体验现实生活中的 MegEngine 推理服务(Face++)
推理服务通常部署在云端服务器(对外提供 gRPC/HTTP 接口请求)或是边缘计算设备(例如用户移动终端)上。 例如 旷视 Face++ 人工智能开放平台 , 为开发者提供人脸识别、人像处理、人体识别、文字识别、图像识别等 AI 能力,里面使用的即 MegEngine 推理引擎。 开发者可以选择使用接入云端服务器上提供的 API 使用服务器上的模型推理, 也可以选择使用封装好的 SDK 服务,在各种设备上离线进行使用。
通过本系列教程的学习,你将能够基于 MegEngine 搭建起自己的推理服务或开发出推理 Demo 应用。
内容安排与组织¶
这套 MegEngine 模型推理部署教程由多个章节组成:
在用户指南的 模型部署总览与流程建议 页面中,对常见情况进行了总结,并给出了最佳实践。 而本套教程将从最原始的情况 —— 即使用与模型训练完全一致环境的,向你演示模型部署的最简概念与形式。 接着与你一同去思考在生产情景下需要考虑的成本和效率问题,从而接触到不同的推理部署情景,并进行实战。
在此之前,如果你还不熟悉 MLOps 的整个流程,建议阅读下一小节的有关介绍:
真实世界的机器学习系统¶
ML Ops: Machine Learning Operations
在 Google 发布的《Hidden Technical Debt in Machine Learning Systems 1 》 论文中指出,机器学习的代码在整个机器学习项目中可能只是很小的一块比例(下图黑色块部分) ——
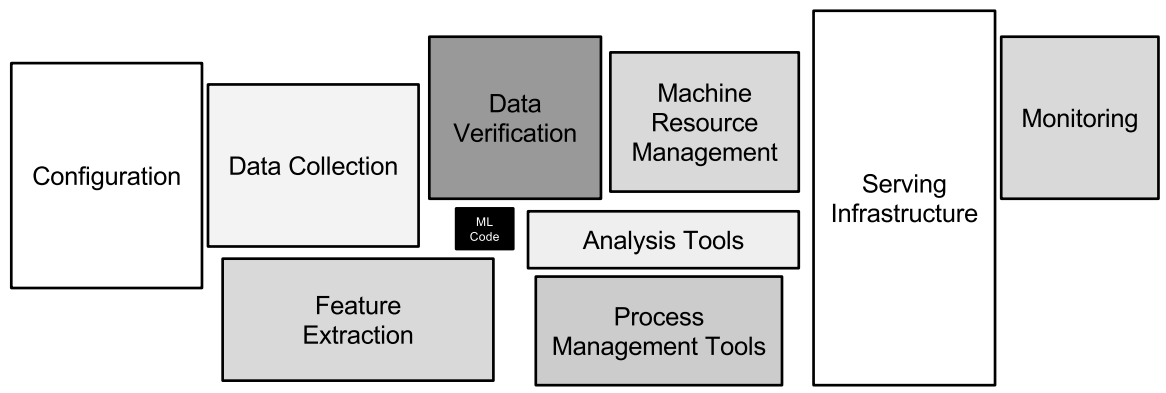
Only a small fraction of real-world ML systems is composed of the ML code, as shown by the small black box in the middle. The required surrounding infrastructure is vast and complex.¶
如果你已经成功地开发出一个机器学习模型 —— 给定输入 \(\mathcal{X}\), 能够如期预测输出 \(\mathcal{Y}\). 我们将这一步称为是模型开发中的概念验证(Proof of concept, POC). 但想要将训练完成的模型落地成生产环境中可用的项目,我们还需要经历其它的一些步骤。 实际上,一个完整的机器学习项目的生命周期将类似于:
MLOps 基本环节:选定范围、数据获取与处理、模型开发、部署应用¶
选定范围:确定项目类型、关键的几个指标(精度、延迟、带宽等等)、预估资源量与排期…
数据:定义数据形式,建立相关的 Baseline, 采集和标注数据等等相关处理…
模型开发:设计出合适的模型结构、调整超参数、在给定数据集上训练并达标…
部署应用:在生产环境中部署模型进行推理,对指标进行监控,进行长期的维护…
通常整个流程不是线性的,而是会在各个环节之间根据结果循环进行调整,以整体达到更好的效果。
参见
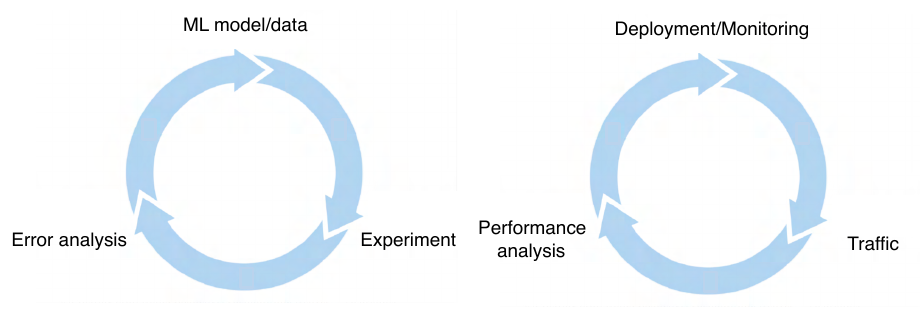
模型部署与模型开发的过程类似,需要在流程中不断迭代调优。¶
Deeplearning.ai 团队的 《 Machine Learning Engineering for Production 》 课程对 MLOps 有着更加详细的解释和案例分析,本系列教程将基于 MegEngine, 专注向你展示部署(Deployment)的基本流程。
参考文献¶
David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. Hidden technical debt in machine learning systems. Advances in neural information processing systems, 2015.