Module base class concept and interface introduction#
Note
The essence of the neural network model can be returned to a series of calculations about Tensor, but it is not convenient to provide only Functional. Module can be regarded as a layer of abstraction after the combination and encapsulation of operators in Functional. In addition to being responsible for defining the basic calculation process, it also supports nesting, providing functional interfaces such as management of internal Tensor, recording of overall status information, and front and back hook processing.
The following are the main contents of the current measure introduced:
According to whether the Tensor in the module is updated by the backpropagation algorithm, we distinguish Parameter and Buffer members;
The neural network modules we designed can be nested with each other, refer to Module nesting relationship and interface;
Some modules have inconsistent ``forward’’ logic during training and testing, so Switch training and testing status is required;
With the help of Module state dictionary, we can easily save and load our model state information;
The module also provides some Module hook for flexible expansion.
See also
For complete interface information, please refer to: py:class:~.module.Module API documentation;
Module is responsible for the
forward'' logic in model training, and the backpropagation ``backwardwill be automatically completed byautodiff.
Parameter and Buffer members#
Each Module maintains a series of important member variables. In order to distinguish Tensor for different purposes, there are the following concept definitions::
The Tensor (such as
weightandbias) updated according to the BP algorithm during the model training process is calledParameter, that is, the parameters of the model;Tensors that do not need to be updated by the backpropagation algorithm (such as the ``mean’’ and ``var’’ statistics used in BN) are called ``Buffer’’;
It can be considered that in a
Module:Module.tensors = Module.parameters + Module.buffers.
We start from the simplest case, take the following SimpleModel as an example (no built-in modules are used):
import megengine.module as M
from megengine import Parameter
class SimpleModel(M.Module):
def __init__(self):
super().__init__()
self.weight = Parameter([1, 2, 3, 4])
self.bias = Parameter([0, 0, 1, 1])
def forward(self, x):
return x * self.weight + self.bias
model = SimpleModel()
Each Parameter and Buffer defined in the __init__ method is managed by the Module where it is located.
Taking Parameter as an example, we can use .parameters() and .named_parameters() to get the corresponding generator:
>>> type(model.parameters())
generator
>>> type(model.named_parameters())
generator
>>> for p in model.parameters():
... print(p)
Parameter([0 0 1 1], dtype=int32, device=xpux:0)
Parameter([1 2 3 4], dtype=int32, device=xpux:0)
>>> for p in model.named_parameters():
... print(p)
('bias', Parameter([0 0 1 1], dtype=int32, device=xpux:0))
('weight', Parameter([1 2 3 4], dtype=int32, device=xpux:0))
Access and modify#
We can directly access the members in the Module, for example as follows:
>>> model.bias
Parameter([0 0 1 1], dtype=int32, device=xpux:0)
Members accessed in this way are modifiable:
>>> model.bias[0] = 1
>>> model.bias
Parameter([1 0 1 1], dtype=int32, device=xpux:0)
See also
Related interface:
parameters/named_parameters/buffers/ :pynamed_buffersIn the following Module state dictionary, a more specific comparison is made with the BN module as an example;
Warning
In fact, these interfaces will recursively get all corresponding members in the module, refer to Module nesting relationship and interface.
Module nesting relationship and interface#
``Module’’ will form a tree structure through nesting, such as the simplest nesting form below:
Implementation code
import megengine.module as M
class BaseNet(M.Module):
def __init__(self):
super().__init__()
self.linear = M.Linear(4, 3)
def forward(self, x):
return self.net(x)
class NestedNet(M.Module):
def __init__(self):
super().__init__()
self.base_net = BaseNet()
self.relu = M.ReLU()
self.linear = M.Linear(3, 2)
def forward(self, x):
x = self.base_net(x)
x = self.relu(x)
x = self.linear(x)
nested_net = NestedNet()
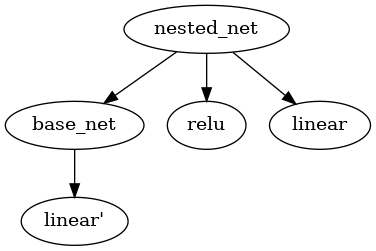
Use: py:meth:~.module.Module.children /
named_childrento get the direct child nodes of the module;Use
modules/named_modulesto get all sub-nodes of the module recursively.
>>> for name, child in nested_net.named_children():
... print(name)
base_net
linear
relu
>>> for name, module in nested_net.named_modules():
... print(name)
base_net
base_net.linear
linear
relu
As in the above sample code, by recursively traversing the sub-nodes, we have obtained the base_net.linear module.
Access nested Module members#
Since each node in the nested structure is a ``Module’’, we can further access its members:
>>> for name, parameter in nested_net.base_net.named_parameters():
... print(name)
linear.bias
linear.weight
>>> nested_net.base_net.linear.bias
Parameter([0. 0. 0.], device=xpux:0)
Note, however, at :ref:Interface parameter-and-buffer are provided recursive traversal nodes Module:
>>> for name, parameter in nested_net.named_parameters():
... print(name)
base_net.linear.bias
base_net.linear.weight
linear.bias
linear.weight
Therefore, it can be found that the bias and weight in base_net have also been acquired. This design is very useful in most cases.
Note
If the logic of obtaining all Parameter by default does not meet the requirements, you can also handle it yourself, such as:
>>> for name, parameter in nested_net.named_parameters():
>>> if 'bias' in name:
>>> print(name)
base_net.linear.bias
linear.bias
In this way, you can only perform some operations on the ``bias’’ type parameters, such as setting a separate initialization strategy.
See also
Models refer to the official offer <https://github.com/MegEngine/Models>various models of the structure of the code _ will deepen the understanding of `` Module`` usage.
Change the Module structure#
The module structure is not immutable, we can replace the sub-nodes inside ``Module’’ (but we need to ensure that the Tensor shape can match):
>>> nested_net.basenet = M.Linear(5, 3)
>>> nested_net
NestedNet(
(basenet): Linear(in_features=5, out_features=3, bias=True)
(relu): ReLU()
(linear): Linear(in_features=3, out_features=2, bias=True)
)
共享 Module 参数#
当 Module 较复杂时,我们可以让两个 Module 共享一部分 Parameter ,
来达到如根据 BP 算法更新的 Tensor时, 只需要更新一份参数的需求。
我们可以基于 Parameter 名字找到目标参数,通过直接赋值的方式来实现 Module 间共享。
nested_net = NestedNet()
base_net = BaseNet()
for name, parameter in base_net.named_parameters():
if (name == "linear.weight"):
nested_net.base_net.linear.weight = parameter
if (name == "linear.bias"):
nested_net.base_net.linear.bias = parameter
Switch training and testing status#
We agree that through the two interfaces: py:meth:~.module.Module.train and eval, Module can be set as training and testing respectively State (the initial default is the training state). This is because some modules that have been provided have different ``forward’’ behaviors during training and testing (eg: py:class:~.module.BatchNorm2d).
Warning
If you forget to switch the state when testing the model, you will get unexpected results;
When switching the module training and testing status, the status of all its sub-modules will be adjusted synchronously, refer to Module nesting relationship and interface.
Module state dictionary#
In the previous section, we introduced that the Tensor in the module can be divided into Parameter and Buffer members two kinds:
>>> bn = M.BatchNorm2d(10)
>>> for name, _ in bn.named_parameters():
... print(name)
bias
weight
>>> for name, _ in bn.named_buffers():
... print(name)
running_mean
running_var
In fact, each module also has a state dictionary STATE_DICT member. Available through: py:meth:~.module.Module.state_dict to get:
>>> bn.state_dict().keys()
odict_keys(['bias', 'running_mean', 'running_var', 'weight'])
All the learnable Tensors are stored in STATE_DICT, that is, not only ``Parameter’’, but also ``Buffer’’.
We can access the information in the dictionary in the form of ``.state_dict()[‘key’]’’:
>>> bn.state_dict()['bias']
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
It seems that there is no difference in usage from directly accessing members, but-
Warning
The data structure type stored in ``value’’ in the Module state dictionary is numpy.ndarray, and it is read-only.
>>> bn.state_dict()['bias'][0] = 1
ValueError: assignment destination is read-only
See also
Through: py:meth:~.module.Module.load_state_dict we can load the Module state dictionary, which is often used to save and load the model training process.
There is also a state dictionary for saving and loading in
Optimizer, refer to Use Optimizer to optimize parameters.For the best practice of saving and loading during model training, please refer to Save and Load Models (S&L).
Note
Use ndarray instead of Tensor structure when saving and loading the Module state dictionary. This is done to ensure better compatibility.